llm-universe-Task4 构建RAG应用
llm-universe-Task4 构建RAG应用
 基于Datawhale的开源课程:地址
基于Datawhale的开源课程:地址
写在前面:
在跟着DW学习途中前几节都是用阿里云服务器,但是好像是服务器配置有点低,进行一系列操作后就会崩溃,但是最近事情,不能老是去调整,所以使用WSL2在本地进行操作
将模型接入LangChain
接入zhipu
这里我采用的智谱的api,所以才用自定义接入,我们利用DW给的代码快速接入
from typing import Any, List, Mapping, Optional, Dict
from langchain_core.callbacks.manager import CallbackManagerForLLMRun
from langchain_core.language_models.llms import LLM
from zhipuai import ZhipuAI
# 继承自 langchain_core.language_models.llms.LLM
class ZhipuAILLM(LLM):
# 默认选用 glm-4 模型
model: str = "glm-4"
# 温度系数
temperature: float = 0.1
# API_Key
api_key: str = None
def _call(self, prompt : str, stop: Optional[List[str]] = None,
run_manager: Optional[CallbackManagerForLLMRun] = None,
**kwargs: Any):
def gen_glm_params(prompt):
'''
构造 GLM 模型请求参数 messages
请求参数:
prompt: 对应的用户提示词
'''
messages = [{"role": "user", "content": prompt}]
return messages
client = ZhipuAI(
api_key=self.api_key
)
messages = gen_glm_params(prompt)
response = client.chat.completions.create(
model = self.model,
messages = messages,
temperature = self.temperature
)
if len(response.choices) > 0:
return response.choices[0].message.content
return "generate answer error"
# 首先定义一个返回默认参数的方法
@property
def _default_params(self) -> Dict[str, Any]:
"""获取调用Ennie API的默认参数。"""
normal_params = {
"temperature": self.temperature,
}
# print(type(self.model_kwargs))
return {**normal_params}
@property
def _llm_type(self) -> str:
return "Zhipu"
@property
def _identifying_params(self) -> Mapping[str, Any]:
"""Get the identifying parameters."""
return {**{"model": self.model}, **self._default_params}
开始接入操作
from zhipuai_llm import ZhipuAILLM
zhipuai_model = ZhipuAILLM(model="chatglm_std", temperature=0, api_key=api_key)
#对model进行设置,使用chatglm_std默认模型
zhipuai_model("你好,请你自我介绍一下!")
你好,我是 智谱清言,是清华大学KEG实验室和智谱AI公司共同训练的语言模型。我的目标是通过回答用户提出的问题来帮助他们解决问题。由于我是一个计算机程序,所以我没有自我意识,也不能像人类一样感知世界。我只能通过分析我所学到的信息来回答问题。
Prompt Templates
from langchain.prompts.chat import ChatPromptTemplate
#引用 ChatPromptTemplate
template = "你是一个翻译助手,可以帮助我将 {input_language} 翻译成 {output_language}."
#固定一个模板
human_template = "{text}"
chat_prompt = ChatPromptTemplate.from_messages([
("system", template), # 设置一个系统预制模板
("human", human_template), #用户输入内容
])
text = "我带着比身体重的行李,\
游入尼罗河底,\
经过几道闪电 看到一堆光圈,\
不确定是不是这里。\
"
messages = chat_prompt.format_messages(input_language="中文", output_language="英文", text=text)
messages
system设置一个预制的prompt模板human用户的prompt
[SystemMessage(content='你是一个翻译助手,可以帮助我将 中文 翻译成 英文.'),
HumanMessage(content='我带着比身体重的行李,游入尼罗河底,经过几道闪电 看到一堆光圈,不确定是不是这里。')]
构建问答链
import sys
sys.path.append("../data_base") # 将父目录放入系统路径中
from zhipuai_embedding import ZhipuAIEmbeddings
from langchain.vectorstores.chroma import Chroma
from dotenv import load_dotenv, find_dotenv
import os
_ = load_dotenv(find_dotenv()) # read local .env file
zhipuai_api_key = os.environ['ZHIPUAI_API_KEY']
# 定义 Embeddings
embedding = ZhipuAIEmbeddings()
persist_directory = '../data_base/vector_db/chroma'
# 加载数据库
vectordb = Chroma(
persist_directory=persist_directory, # 允许我们将persist_directory目录保存到磁盘上
embedding_function=embedding
)
看一下储存的数据量
print(f"向量库中存储的数量:{vectordb._collection.count()}")
向量库中存储的数量:20
创建LLM
#这里我是用的是智谱的api
import os
ZHIPUAI_API_KEY = os.environ["ZHIPUAI_API_KEY"]
from langchain_openai import ChatOpenAI
# 需要下载源码
from zhipuai_llm import ZhipuAILLM
llm = ZhipuAILLM(model="chatglm_std", temperature=0, api_key=ZHIPUAI_API_KEY)
llm.invoke("请你自我介绍一下自己!")
'你好,我是 智谱清言,是清华大学KEG实验室和智谱AI公司共同训练的语言模型。我的目标是通过回答用户提出的问题来帮助他们解决问题。由于我是一个计算机程序,所以我没有自我意识,也不能像人类一样感知世界。我只能通过分析我所学到的信息来回答问题。'
构建回答链
question_1 = "什么是南瓜书?"
question_2 = "王阳明是谁?"
result = qa_chain({"query": question_1})
print("大模型+知识库后回答 question_1 的结果:")
print(result["result"])

自己回答的效果:
prompt_template = """请回答下列问题:
{}""".format(question_1)
### 基于大模型的问答
llm.predict(prompt_template)
' 南瓜书是一本针对数据科学和机器学习领域的教材,旨在帮助学习者更好地理解和掌握相关的数学知识。它由开源组织Datawhale发起,团队成员谢文睿、秦州牵头,对教材中难以理解的公式进行解析,对跳跃性较大的公式进行推导,帮助学习者解决数学难题。南瓜书已经得到广大学习者的认可,并在GitHub上获得了超过1.1万的星标。'
看来智谱已经学习到DW团队的南瓜书的内容了
用Streamlit部署
import streamlit as st
from langchain_openai import ChatOpenAI
第一次运行发现没有 streamlit库,那我们先pip一个
pip install streamlit
进入所部署的streamlit

一个简单框架:
import streamlit as st
from langchain_openai import ChatOpenAI
st.title('🦜🔗 动手学大模型应用开发--BX')
openai_api_key = st.sidebar.text_input('OpenAI API Key', type='password')
def generate_response(input_text):
llm = ChatOpenAI(temperature=0.7, openai_api_key=openai_api_key)
st.info(llm(input_text))
with st.form('my_form'):
text = st.text_area('Enter text:', 'What are the three key pieces of advice for learning how to code?')
submitted = st.form_submit_button('Submit')
if not openai_api_key.startswith('sk-'):
st.warning('Please enter your OpenAI API key!', icon='⚠')
if submitted and openai_api_key.startswith('sk-'):
generate_response(text)
接下来,看看效果!
我在这里用的windows的wsl2----Ubuntu
#先进入对应的目录下
conda activate llm-universe
streamlit run streamlit_app.py
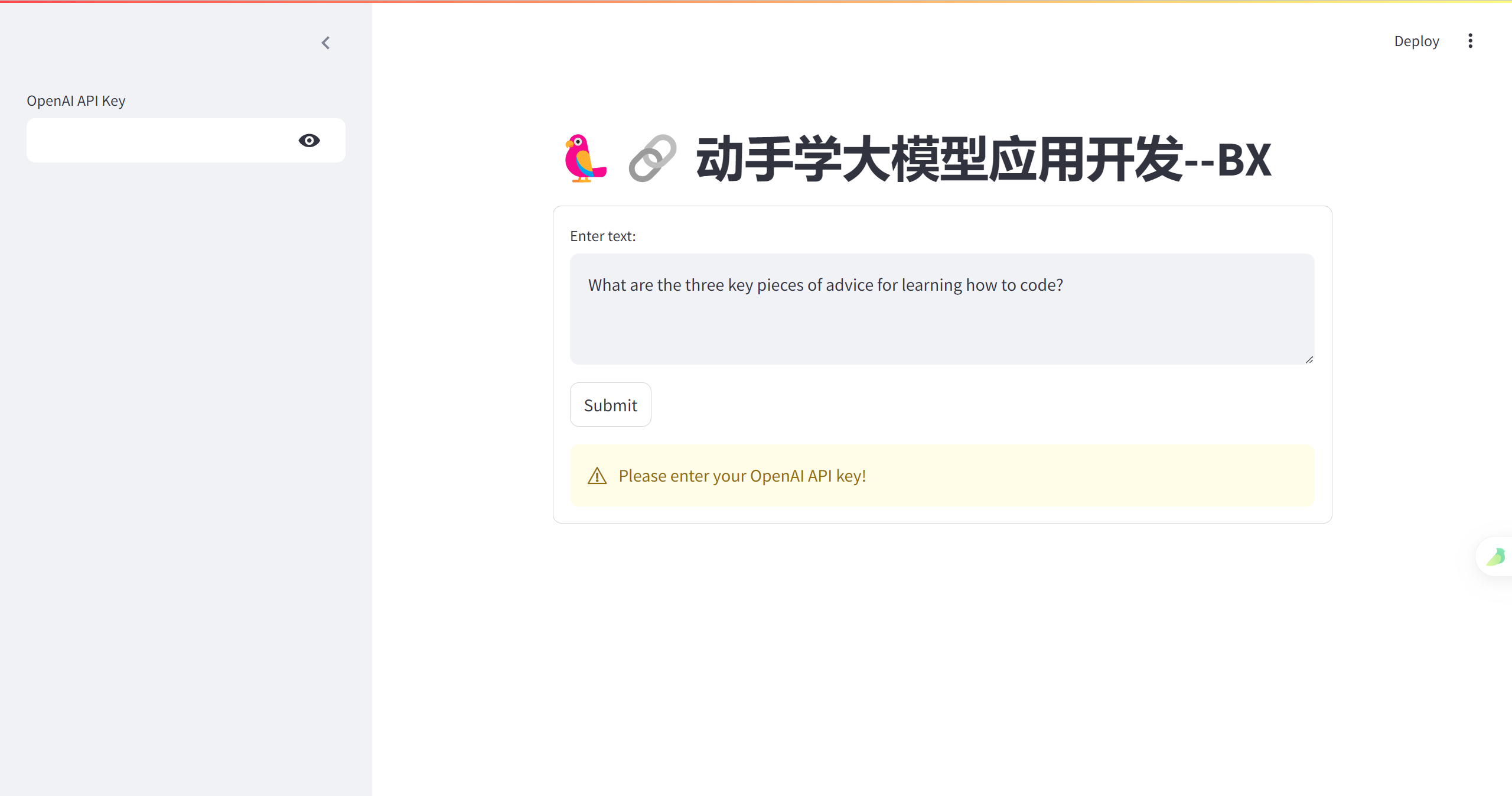
功能比较完善后
import streamlit as st
from langchain_openai import ChatOpenAI
import os
from langchain_core.output_parsers import StrOutputParser
from langchain.prompts import PromptTemplate
from langchain.chains import RetrievalQA
import sys
sys.path.append("../data_base") # 将父目录放入系统路径中
from zhipuai_embedding import ZhipuAIEmbeddings
from langchain.vectorstores.chroma import Chroma
from langchain.memory import ConversationBufferMemory
from langchain.chains import ConversationalRetrievalChain
from dotenv import load_dotenv, find_dotenv
_ = load_dotenv(find_dotenv()) # read local .env file
#export OPENAI_API_KEY=
#os.environ["OPENAI_API_BASE"] = 'https://api.chatgptid.net/v1'
zhipuai_api_key = os.environ['ZHIPUAI_API_KEY']
def generate_response(input_text, openai_api_key):
llm = ChatOpenAI(temperature=0.7, openai_api_key=openai_api_key)
output = llm.invoke(input_text)
output_parser = StrOutputParser()
output = output_parser.invoke(output)
#st.info(output)
return output
def get_vectordb():
# 定义 Embeddings
embedding = ZhipuAIEmbeddings()
# 向量数据库持久化路径
persist_directory = '../data_base/vector_db/chroma'
# 加载数据库
vectordb = Chroma(
persist_directory=persist_directory, # 允许我们将persist_directory目录保存到磁盘上
embedding_function=embedding
)
return vectordb
#带有历史记录的问答链
def get_chat_qa_chain(question:str,openai_api_key:str):
vectordb = get_vectordb()
llm = ChatOpenAI(model_name = "gpt-3.5-turbo", temperature = 0,openai_api_key = openai_api_key)
memory = ConversationBufferMemory(
memory_key="chat_history", # 与 prompt 的输入变量保持一致。
return_messages=True # 将以消息列表的形式返回聊天记录,而不是单个字符串
)
retriever=vectordb.as_retriever()
qa = ConversationalRetrievalChain.from_llm(
llm,
retriever=retriever,
memory=memory
)
result = qa({"question": question})
return result['answer']
#不带历史记录的问答链
def get_qa_chain(question:str,openai_api_key:str):
vectordb = get_vectordb()
llm = ChatOpenAI(model_name = "gpt-3.5-turbo", temperature = 0,openai_api_key = openai_api_key)
template = """使用以下上下文来回答最后的问题。如果你不知道答案,就说你不知道,不要试图编造答
案。最多使用三句话。尽量使答案简明扼要。总是在回答的最后说“谢谢你的提问!”。
{context}
问题: {question}
"""
QA_CHAIN_PROMPT = PromptTemplate(input_variables=["context","question"],
template=template)
qa_chain = RetrievalQA.from_chain_type(llm,
retriever=vectordb.as_retriever(),
return_source_documents=True,
chain_type_kwargs={"prompt":QA_CHAIN_PROMPT})
result = qa_chain({"query": question})
return result["result"]
# Streamlit 应用程序界面
def main():
st.title('🦜🔗 BX---动手学大模型应用开发')
openai_api_key = st.sidebar.text_input('OpenAI API Key', type='password')
# 添加一个选择按钮来选择不同的模型
#selected_method = st.sidebar.selectbox("选择模式", ["qa_chain", "chat_qa_chain", "None"])
selected_method = st.radio(
"你想选择哪种模式进行对话?",
["A模式", "B模式", "C模式"],
captions = ["不使用检索问答的普通模式", "不带历史记录的检索问答模式", "带历史记录的检索问答模式"])
# 用于跟踪对话历史
if 'messages' not in st.session_state:
st.session_state.messages = []
messages = st.container(height=300)
if prompt := st.chat_input("Say something"):
# 将用户输入添加到对话历史中
st.session_state.messages.append({"role": "user", "text": prompt})
if selected_method == "None":
# 调用 respond 函数获取回答
answer = generate_response(prompt, openai_api_key)
elif selected_method == "qa_chain":
answer = get_qa_chain(prompt,openai_api_key)
elif selected_method == "chat_qa_chain":
answer = get_chat_qa_chain(prompt,openai_api_key)
# 检查回答是否为 None
if answer is not None:
# 将LLM的回答添加到对话历史中
st.session_state.messages.append({"role": "assistant", "text": answer})
# 显示整个对话历史
for message in st.session_state.messages:
if message["role"] == "user":
messages.chat_message("user").write(message["text"])
elif message["role"] == "assistant":
messages.chat_message("assistant").write(message["text"])
if __name__ == "__main__":
main()
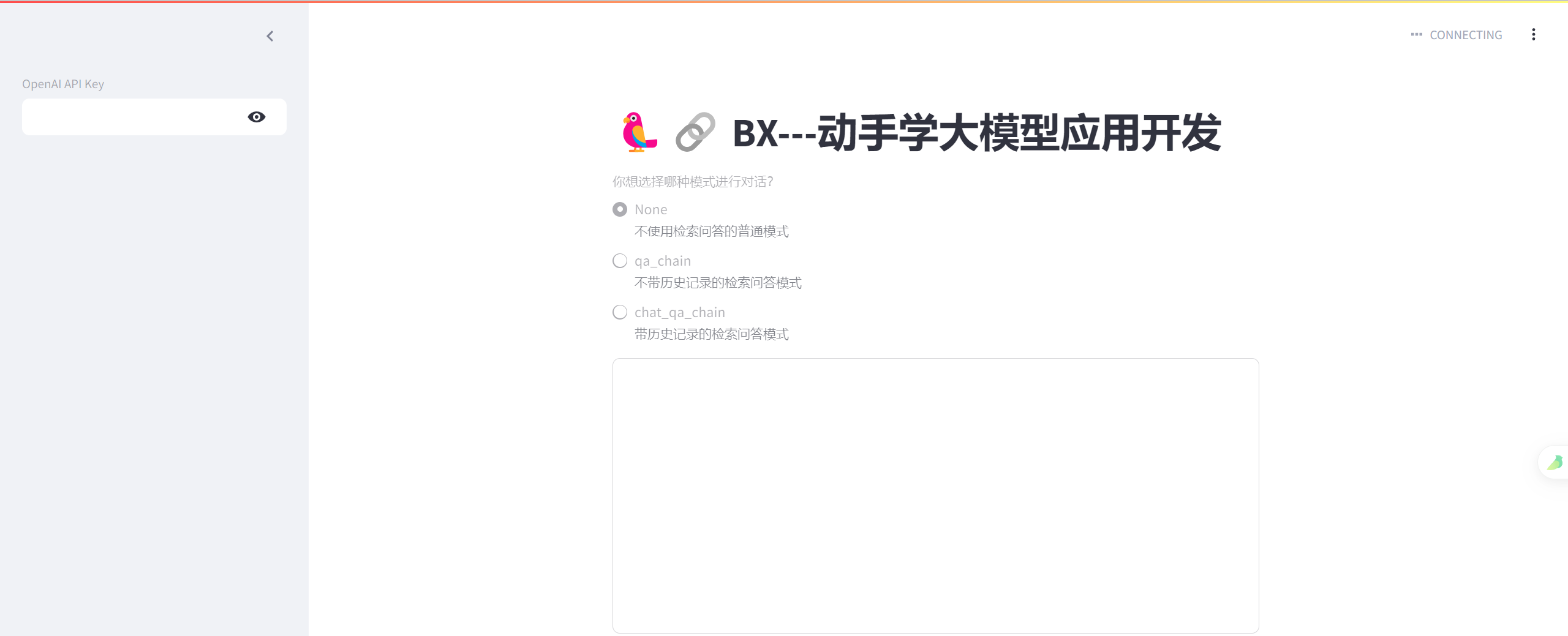
这只是个示例,具体功能还不能使用,由于DW教程给的是基于openai的api,这里还没有改为基于智谱和生成的向量库的内容
利用智谱的模型生成图片

from zhipuai import ZhipuAI
client = ZhipuAI(api_key=my_api)
response = client.images.generations(
model="cogview-3", #调用智谱的图片生成模型“cogview-3”
prompt="宇宙飞船",
#这个大概一张图片是0.1元
)
print(response.data[0].url)
这个调用的费用在0.1元一张