llm-universe-Task6 对案例学习和总结
Task 6 对案例学习总结

本次内容如下:
- 对两个精选案例进行学习
- 对之前的内容进行总结
- 对之前所做的东西进行优化
对案例学习
1.个人知识库助手
具体项目界面如下:
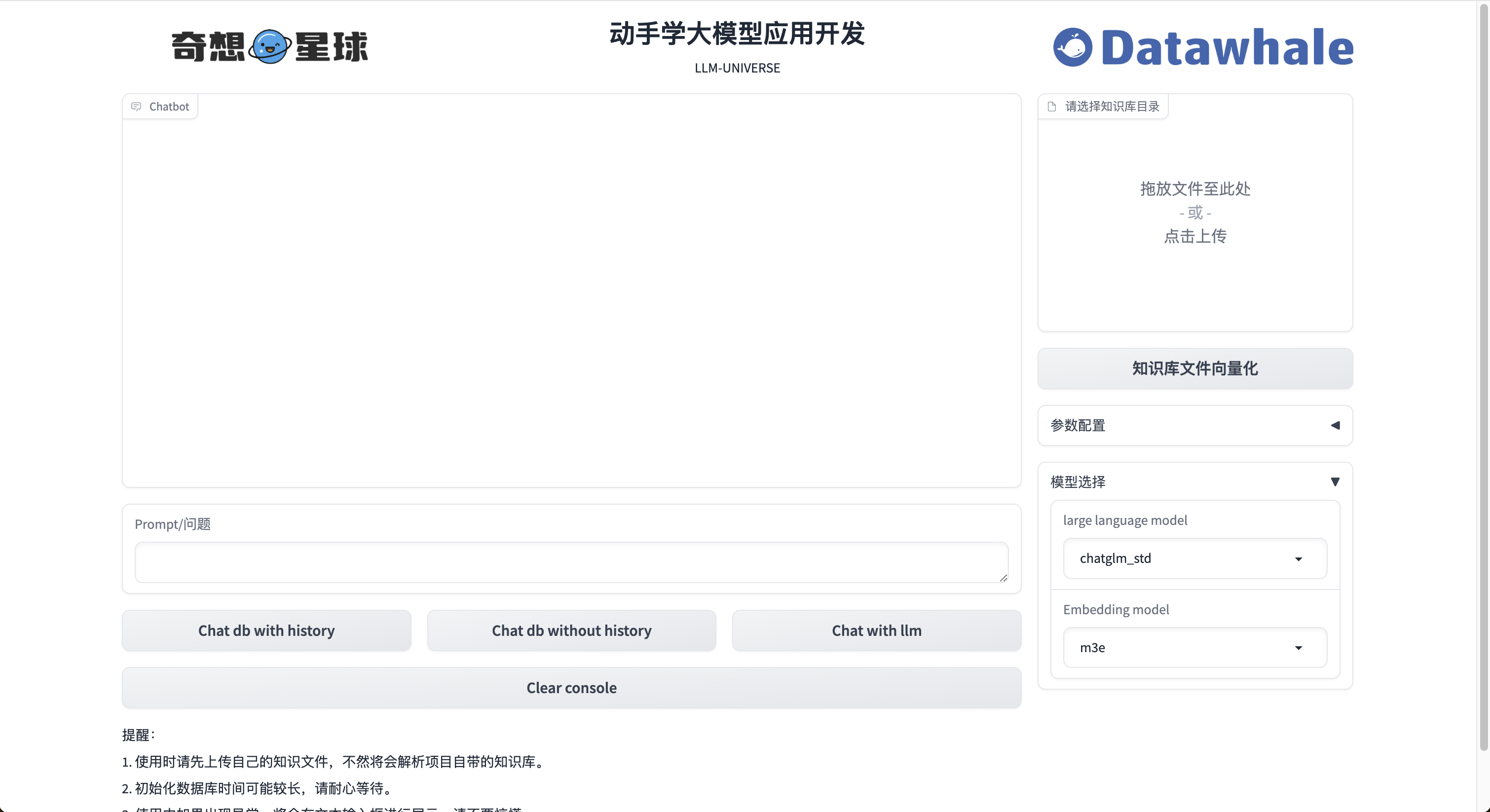
这里我采用wsl本地复现一下
项目地址:https://github.com/logan-zou/Chat_with_Datawhale_langchain
- 来到对应项目git的目录下
cd Chat_with_Datawhale_langchain
- 激活环境
**由于之前学习已经适用conda配置过一会环境了,所以直接采用 **llm-universe
conda init
conda activate llm-universe
#安装一下额外所需要的库
pip install -r requirements.txt
#注意这里下载可能需要外网,这个自行处理,或者连接国内镜像
cd serve
uvicorn api:app --reload
- 运行项目
cd llm-universe/project/serve
python run_gradio.py -model_name='chatglm_std' -embedding_model='m3e' -db_path='../../data_base/knowledge_db' -persist_path='../../data_base/vector_db'
核心技术栈
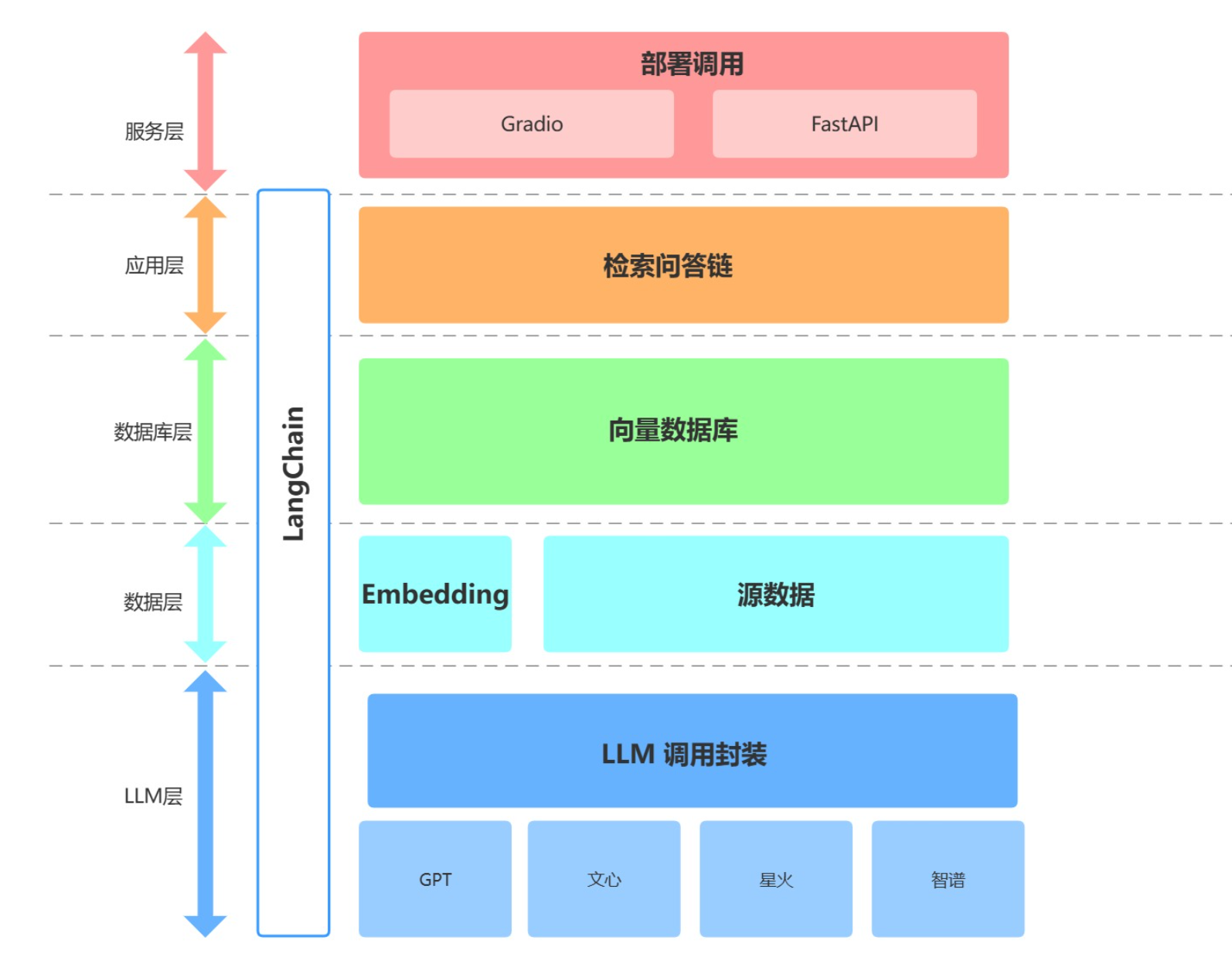
由图可知在服务层调用了 FastAPI 和 gradio
作者提供了通过 demo和 api这两种方式来访问这个应用
gradio框架我们之前在Task 5 学习使用过
Gradio是一个开源的Python库,用于快速构建机器学习模型的用户界面和演示应用。以下是Gradio的主要特点和优势:
- 易用性: Gradio设计直观,易于学习和使用。只需几行Python代码就可以创建交互式界面。
- 专为机器学习设计: Gradio特别适用于机器学习项目,可以简单直观地测试、分享和展示模型。
- 纯Python实现: 使用Gradio不需要前端开发经验,所有代码都用Python编写。
- 自动生成UI: 根据指定的输入和输出类型,Gradio可以自动生成相应的用户界面元素。
Fastapi:
**官方网址: **https://fastapi.tiangolo.com/
FastAPI是一个现代、高性能的Python Web框架,用于构建API。以下是FastAPI的主要特点和优势:
- 高性能: FastAPI的性能与NodeJS和Go语言相当,是最快的Python框架之一。
- 易于使用: 设计直观,易于学习,可以减少开发时间和代码重复。
- 基于Python类型提示: 利用Python 3.6+的标准类型提示进行数据验证、序列化和反序列化。
- 自动文档生成: 基于代码自动生成交互式API文档(使用Swagger UI和ReDoc)。
- 异步支持: 原生支持使用Python的async/await语法进行异步编程。
- 数据验证: 使用Pydantic进行强大的模式验证和序列化。
- 基于标准: 完全兼容OpenAPI(前身为Swagger)和JSON Schema标准。
- 依赖注入: 包含强大的依赖注入系统,用于处理共享逻辑(如数据库会话或认证)。
- 安全特性: 内置支持认证和授权机制。
- 生产就绪: 框架设计默认遵循最佳实践,可生成生产就绪的代码。
FastAPI不仅限于构建API,还可用于其他Web框架用例,如使用Jinja2模板引擎提供传统网页,或构建基于WebSocket的应用。
我之前并没接触过这个 Fastapi阅读了一下文档,了解了一下
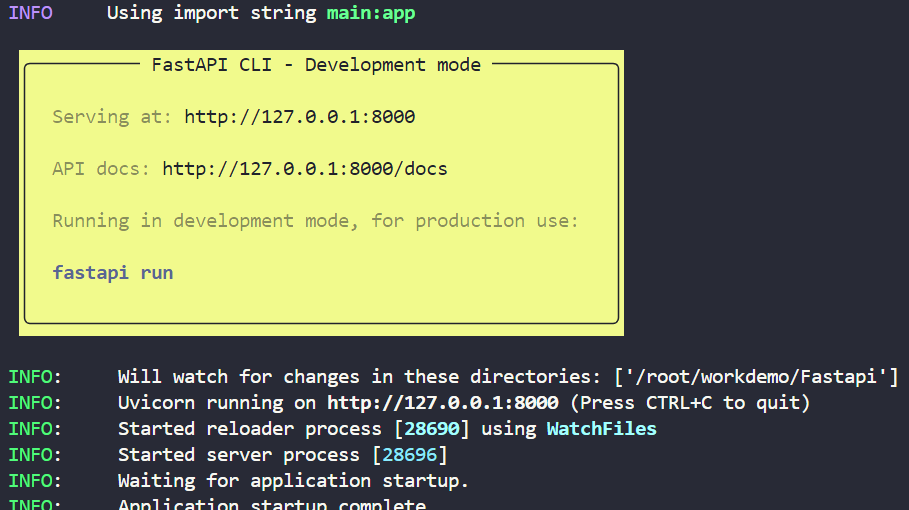

这是一个很好的****RAG项目,相当于是对DW-llm项目的优化和升级,让用户上传属于自己的知识,帮助构建一个属于自己的个人助手
RAG(Retrieval-Augmented Generation)是一种优化大型语言模型(LLM)输出的技术,它通过引用模型训练数据之外的权威知识库来生成响应。以下是RAG的主要特点和优势:
工作原理:
- RAG在LLM生成响应之前,先从外部数据源检索相关信息。
- 它使用嵌入语言模型将外部数据转换为向量表示,存储在向量数据库中。
- 用户查询被转换为向量,与数据库中的向量进行相关性匹配。
- 检索到的相关信息与用户输入一起提供给LLM,以生成更准确的响应
具体代码学习
def model_to_llm(model:str=None, temperature:float=0.0, appid:str=None, api_key:str=None,Spark_api_secret:str=None,Wenxin_secret_key:str=None):
"""
星火:model,temperature,appid,api_key,api_secret
百度问心:model,temperature,api_key,api_secret
智谱:model,temperature,api_key
OpenAI:model,temperature,api_key
"""
if model in ["gpt-3.5-turbo", "gpt-3.5-turbo-16k-0613", "gpt-3.5-turbo-0613", "gpt-4", "gpt-4-32k"]:
if api_key == None:
api_key = parse_llm_api_key("openai")
llm = ChatOpenAI(model_name = model, temperature = temperature , openai_api_key = api_key)
elif model in ["ERNIE-Bot", "ERNIE-Bot-4", "ERNIE-Bot-turbo"]:
if api_key == None or Wenxin_secret_key == None:
api_key, Wenxin_secret_key = parse_llm_api_key("wenxin")
llm = Wenxin_LLM(model=model, temperature = temperature, api_key=api_key, secret_key=Wenxin_secret_key)
elif model in ["Spark-1.5", "Spark-2.0"]:
if api_key == None or appid == None and Spark_api_secret == None:
api_key, appid, Spark_api_secret = parse_llm_api_key("spark")
llm = Spark_LLM(model=model, temperature = temperature, appid=appid, api_secret=Spark_api_secret, api_key=api_key)
elif model in ["chatglm_pro", "chatglm_std", "chatglm_lite"]:
if api_key == None:
api_key = parse_llm_api_key("zhipuai")
llm = ZhipuAILLM(model=model, zhipuai_api_key=api_key, temperature = temperature)
else:
raise ValueError(f"model{model} not support!!!")
return llm
**==该代码定义了一个名为 **model_to_llm 的函数,用于根据指定的模型和相关参数初始化相应的聊天模型接口对象。该函数支持多个语言模型平台,包括 OpenAI、百度Wenxin)、星火(Spark)、和智谱(ZhipuAI)。函数根据传入的模型名称选择相应的平台,并通过相应的 API 密钥和其他必要参数进行初始化。:==
2. 人情世故大模型
这个案例十分有趣,是一非常具有特色的项目

对项目复现尝试一下
git clone https://github.com/SocialAI-tianji/Tianji.git\
conda create -n TJ python=3.11
conda activate TJ
pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple

分析和学习

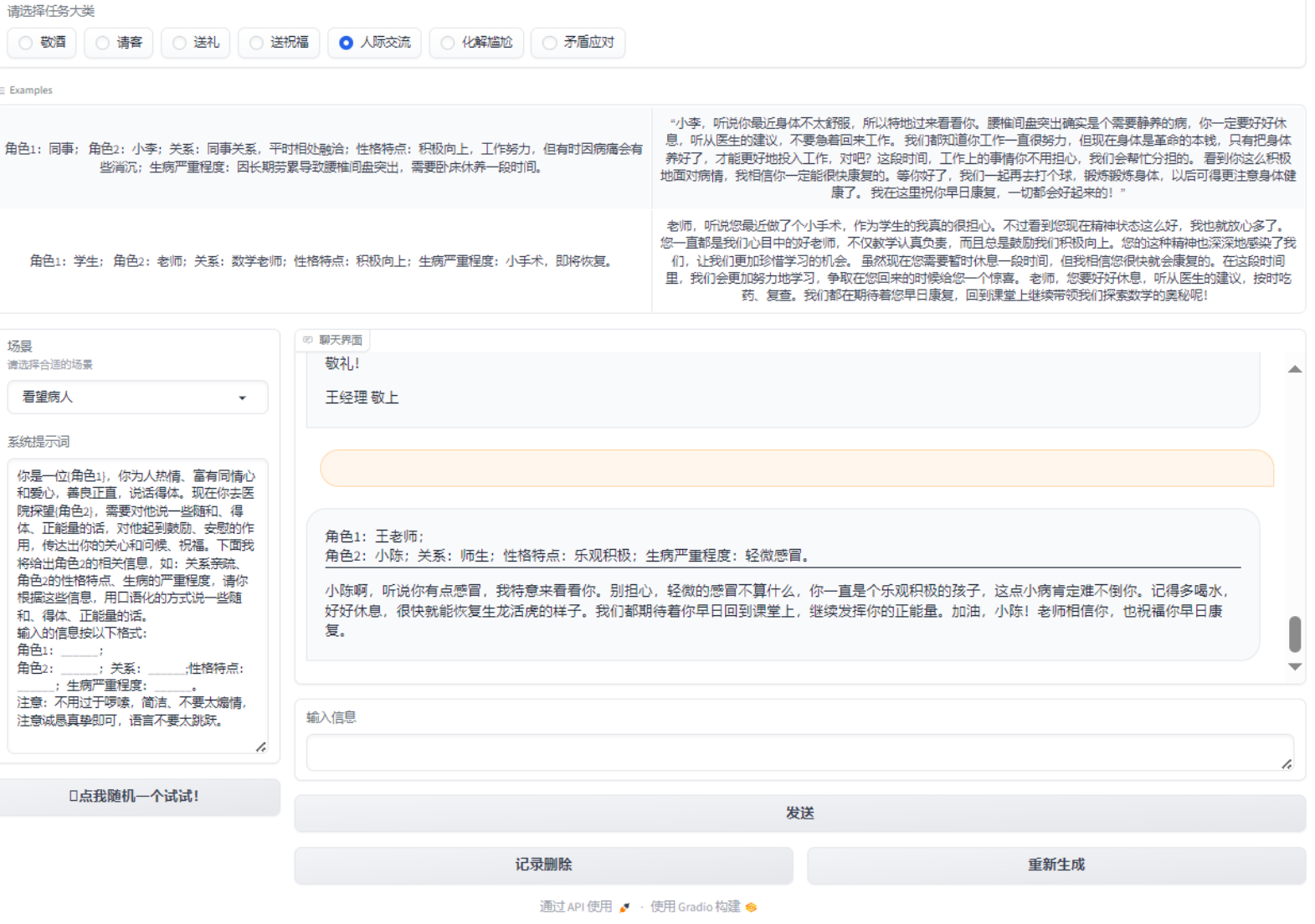
-
通过内置 system prompt ,通过系统提示词让大模型进行输出
-
通过向量数据库,检索知识库的内容
-
Agent(这部分我还有待进一步地学习)

MetaGPT
 MetaGPT是一个多智能体框架,旨在通过将不同的GPT模型分配到不同的角色中,形成一个协作的软件实体,以解决复杂任务3。它由中国团队开发,主要应用于软件开发等场景,利用标准作业程序(SOP)来协调基于大语言模型的多智能体系统,实现元编程技术5。MetaGPT的架构分为两层:基础组件层和协作层,其中基础组件层侧重于个体代理操作并促进系统范围内的信息交换,介绍了核心构建块,如环境、内存、角色、操作和工具
MetaGPT是一个多智能体框架,旨在通过将不同的GPT模型分配到不同的角色中,形成一个协作的软件实体,以解决复杂任务3。它由中国团队开发,主要应用于软件开发等场景,利用标准作业程序(SOP)来协调基于大语言模型的多智能体系统,实现元编程技术5。MetaGPT的架构分为两层:基础组件层和协作层,其中基础组件层侧重于个体代理操作并促进系统范围内的信息交换,介绍了核心构建块,如环境、内存、角色、操作和工具
......